Potential Pitfalls: Unexpected Events
James Bond's solution ...
-

Coping With The Unexpected
-
Most of us haven’t had a cow wander on to a road in front of us while we’re driving. Still, it’s the type of situation Google is wisely anticipating. A significant challenge for self-driving cars will be handing edge cases, essentially rare situations on the road. As investor Chris Dixon has written, machine learning can quickly solve 80 percent of any problem, but getting the full 100 percent is extremely difficult.
Sure, a self-driving car just drove across the country, but it had the benefit of being on highways, an easy situation for self-driving cars. And the company behind the trip, Delphi, admits the car didn’t do 100 percent of the driving.
It will prove difficult for Google, Delphi or any carmaker to prepare its self-driving cars for all of the odd circumstances the cars will occasionally encounter. Passengers appear very unlikely to be trusted to take over in hairy situations. Google has removed the steering wheel and pedals from its latest prototype, amid concerns that passengers can’t be trusted to effectively take over when necessary.
But a patent Google received last week offers a window into the tech company’s plans for handling these edge cases, such as a few cows in your path.
Google has devised a system for identifying when an autonomous car is in a “stuck position,” and laid out plans for how to get out of the situation. A stuck position is a circumstance where a car can’t get to its final destination without violating some of its rules. For example it might be programmed to only drive on a road and not the shoulder. So what happens when a car breaks down in the lane in front of it?
Google’s patent calls for an assistance center to resolve any situation where the autonomous car can’t follow its planned route. Once the car determines it’s stuck, it will request help from the center, which would rely on a “human expert and/or an expert system” to resolve the issue.
The car sends its location plus data from its sensors. The expert then would suggest a new route, or may request more information, such as images or live video from the car’s cameras to better understand the situation. The patent includes an interface the expert at the assistance center would use. The patent, which leaves many options open for how exactly such a system could work, says the interface also might be controlled by a passenger in the car. Here’s how it could map a route around a group of cows:
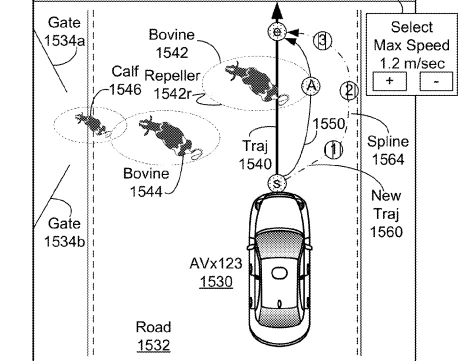 Here the “draw new [trajectory]” button is selected and a new route is drawn to get around the bovine. (U.S. Patent and Trademark Office)
Here the “draw new [trajectory]” button is selected and a new route is drawn to get around the bovine. (U.S. Patent and Trademark Office)
The patent devotes a lot of time to figuring out exactly when a car is stuck and when it isn’t. Google points out that being able to effectively determine when a car is stuck will reduce the demands on expert needed to operate the fleet. The less often experts have to intervene, the lower Google or anyone’s cost to run a network of self-driving cars will be. If the car can’t tell the difference between when it’s really stuck, and when it just needs to be patient, that could be a disaster for Google. Imagine hundreds of self-driving cars stuck in heavy traffic as a concert or sport event lets out, all contacting and overwhelming the assistance center. At the same time, you wouldn’t want a self-driving car stopped behind a double-parked car for five minutes, thinking it’s just stuck in traffic.
Google envisions taking into account a wealth of information before determining if a car is stuck. It will consider the location and the time of day. Is the car near a school as it’s letting out? Or a sports arena shortly after games usually end? Those are situations where a car stuck in traffic might learn it should just be patient.
-
Most of us haven’t had a cow wander on to a road in front of us while we’re driving. Still, it’s the type of situation Google is wisely anticipating. A significant challenge for self-driving cars will be handing edge cases, essentially rare situations on the road. As investor Chris Dixon has written, machine learning can quickly solve 80 percent of any problem, but getting the full 100 percent is extremely difficult.